
Before leaving for a well earned winter break, we bring news from the Digital Research Data and Human Science (DRDHum) conference organized by the University of Eastern Finland in Joensuu. This DRDHum edition (10-12 December 2024) attracted more than 100 scholars of the digital age. FIN-CLARIAH hosted a workshop that brought an early Christmas present to some 25 participants who were introduced a suite of tools designed to make sense of web data. The term “sense-making” here includes not only the analytical interpretation of dataset contents but also their automatic enrichment and the extraction of relevant segments for deeper analysis. This comprehensive toolkit is needed for supporting the whole research cycle, from raw data extraction and preprocessing to interpretation.

First, Risto Turunen (DARIAH-FI) introduced the big picture of the research infrastructure and argued that in a land with limited DH resources, it makes sense to cooperate and specialise. For example, the hosting organization, the University of Eastern Finland, is great at doing linguistics with social media data and has produced a very useful tool for this purpose, Nordic Tweet Stream, that can be used for studying the Nordic Twitter from 2013 to 2023. Using the research infrastructure, we can scale local innovations such as this to the national level so that the fruits of labor can be enjoyed by a wider population of humanists and social scientists.
The national FIN-CLARIAH infrastructure consists of two key components: DARIAH-FI, which supports a wide range of humanities and social sciences, and FIN-CLARIN, which specialises in language technology and linguistic data. Mietta Lennes highlighted the services of the latter, The Language Bank of Finland (see slides). For example, the KORP interface is a versatile and powerful tool, capable of analysing datasets that are way too large for local computers, such as the extensive Suomi24 Corpus.
Erik Henriksson introduced a selection of tools (see slides) from the internationally renowned TurkuNLP Group. For example, they offer a register classifier (see Colab) that can automatically categorise online texts into registers such as opinion blogs, reviews, or promotional descriptions. It is easy to see how many common research designs could benefit from automatically identifying these categories in web data, whether to focus on them or to exclude them. Or, perhaps you are interested in the issue of toxic language online? To find even more instances of toxicity, you might consider using the toxicity classifier (see Colab). While these tools are not yet accessible through a graphical user interface, user-friendly digital notebooks make their use easier for those without strong coding skills.
Ville Vaara from the University of Helsinki demonstrated a tool specifically designed for large-scale datasets (see slides), featuring easy indexing, comprehensive data analysis, and efficient data subsetting (add hyper link to the presentation). The potential of this tool became clear, though the live demo (see Colab) encountered some issues – possibly due to high user traffic, as the room was at full capacity.
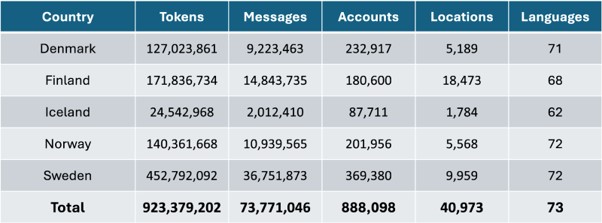
The final presentation was given by the local star, Masoud Fatemi (UEF), who introduced the latest version of the Nordic Tweet Stream (NTS). This tool will surely lead to many concrete research findings in the near future, as it contains almost one billion words of data from Finland, Sweden, Norway, Denmark, and Iceland. The audience was interested and gave ideas for further functionalities, such as the possibility of searching beyond words using multilingual large language models.
This is precisely the purpose of our events: to stay alive, research infrastructures must be connected to the grassroots, both in the humanities and natural sciences. And that is why our research infrastructure will be at the next DRDHum conference in Turku 2026.
Header: Erik Henriksson from TurkuNLP, introduces tools to make sense of web data . Photo by Reza Saberi.