
A Word from the Writer
Hello there! This is my first blog post, so I feel that an introduction is necessary. My name is Elias, I am a master’s degree student at the University of Helsinki, and I have been entrusted with helping out in the communications department at DARIAH-FI. One of the tasks is exactly this – writing blog posts about new projects and current goals of the infrastructure. While many digital humanities projects are primarily intended to be used by expert researchers and scholars, I believe that they should also be accessible for the wider audience that might need more guidance, such as students of various degrees and majors. I am very honoured that, as a first year student of digital humanities and research assistant, I get to meet renowned researchers and try out and talk about a variety of research projects and infrastructures in this field. I hope that my experience and message can reach people who might be a bit lost in the space of DH.
Introduction to the Sampo
With that out of the way, let’s talk about ParlamenttiSampo. ParlamenttiSampo is a LoD (linked open data) research project and infrastructure revolving around Finnish parliamentary data, particularly speeches from the plenary sessions, developed by researchers from Aalto University and University of Helsinki and overseen by the professor Eero Hyvönen. It is part of a bigger series making use of the Sampo model, which is designed with collaborative data sharing and analysis in mind. The main goal of the project is to make parliamentary speech data more accessible and usable for researchers in various areas, primarily political, as it builds ground for important conversations about politics, the people involved in it and ideas that are brought forth by them. The results of the project were presented on November 10, 2022, with the service and website (https://parlamenttisampo.fi/fi/) available for access and open use from February 14, 2023. More specific information on the development of the project as well as the project itself can be found on the Semantic Computing Research Group’s (SeCo) webpage https://seco.cs.aalto.fi/projects/semparl/en/, available both in Finnish and in English.
ParlamenttiSampo – Perspective
The main page’s layout is very clear and concise, with links to three different parts of the infrastructure (Puheenvuorot 2015-2022 – “Speeches 2015-2022”, Henkilöt – “People” and Puheenvuorot eri ajanjaksoilta – “Speeches from different periods” respectively) in the middle of the interface, with additional links to faceted searches, information and a feedback form in the top right corner. An English version of the website is currently a work in progress, so I will only be looking at the Finnish one – which makes sense, considering the fact that it contains Finnish-language data. Each category branches off accordingly, with more information available the deeper you dig. The advanced categories are incredibly detailed, with available information ranging from names and nationalities to exact occupations and associated political groups.
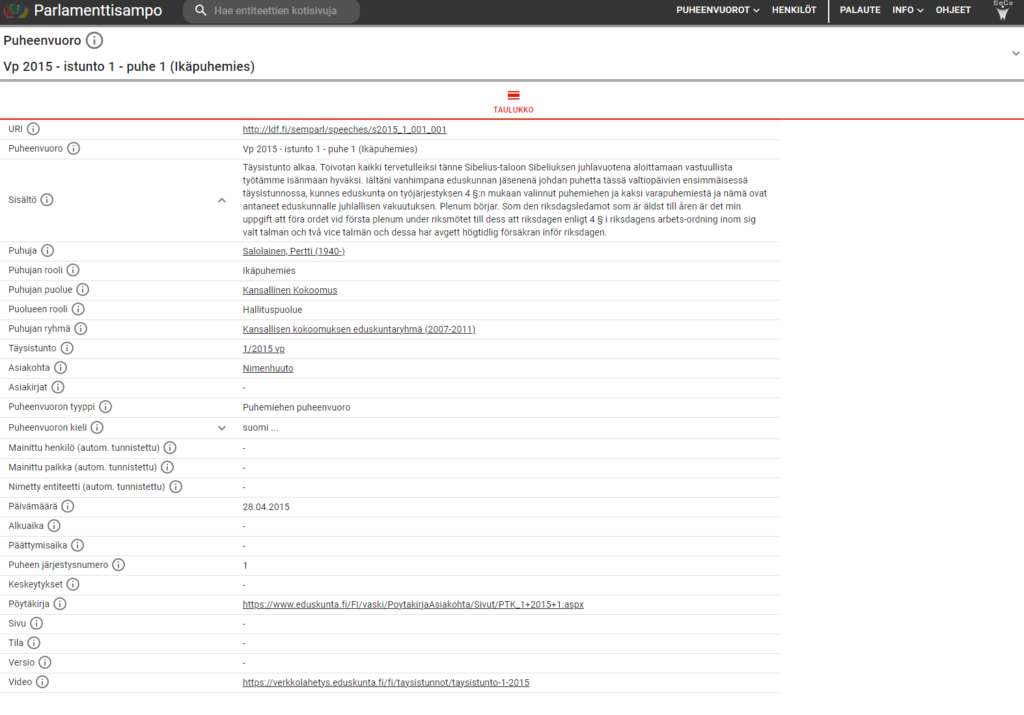
Each speech has its own page on the website with as much metadata as is known included. There are also statistics for the whole dataset available that can be faceted and searched through accordingly. The project is accompanied by maps and graphs to visualise the data seamlessly. The “People” category (henkilöt) is available for download as a .csv file and can also be accessed through SPARQL. Just the metadata itself is, of course, an incredibly valuable resource when it comes to digital humanities (and more). With how rich it is in ParlamenttiSampo, it can be used for many different things and projects, while simultaneously being easily accessible – which is what makes it particularly invaluable. A simple use case would be to check word frequencies in speeches – here, we take the word kapitalismi (“capitalism”), and by putting it in the search on ParlamenttiSampo, we can get both a pie chart with the distribution of that specific word in speeches of various parties (Figure 1), as well as it’s distribution in all speeches over the years (Figure 2). This already provides one with a foundation for an analysis.
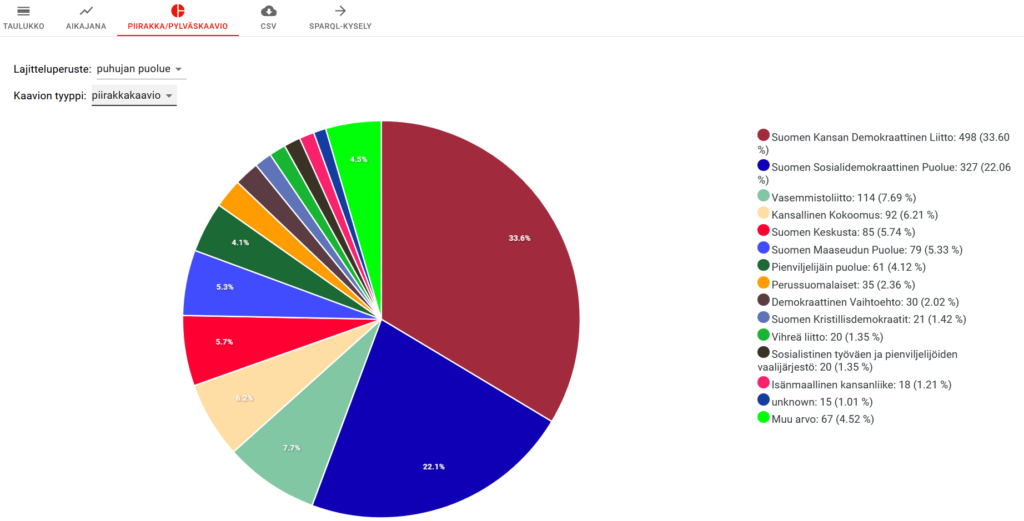
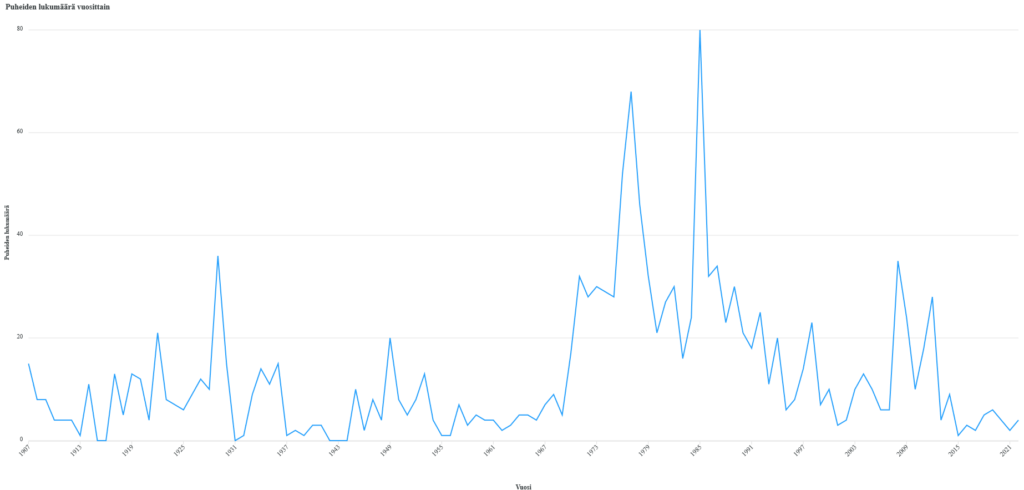
Conclusions
While not being an expert, from my point of view, it is very easy for everyone to use ParlamenttiSampo. Whether one wants to analyse specific parts of the metadata, quantify certain words in speeches to find out interesting phenomena, try out a network analysis of people involved in the Finnish parliament, and more, it is all possible and made simpler with the help of this project and the tools available. I would be very interested to see future projects and developments including ParlamenttiSampo, as I am sure it will be an invaluable tool for many to come.
This concludes today’s post! I would like to thank you for reading and I hope that my insight has been and will be valuable to some, and that I can continue making my own mark in DARIAH-FI, as well as digital humanities overall.