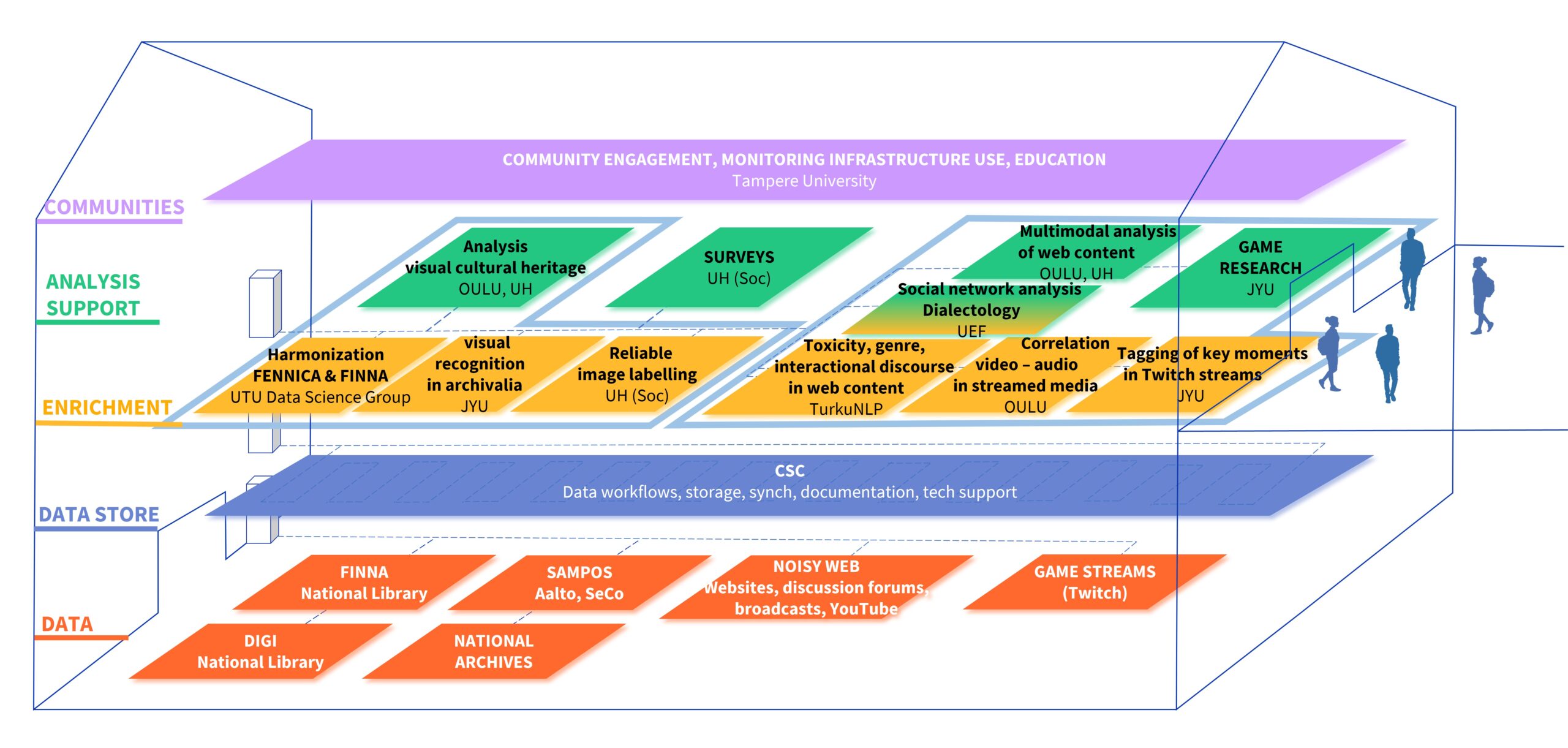
On Friend’s Day, as Finns know Valentine’s Day, all partners of the DARIAH-FI consortium gathered on Zoom for the first time in its renewed configuration. Here is an overview of the plan ahead, as it was presented by participants. I have done my best to bring the workplan and the teams behind it under one roof, in this blog post, but also with the image above. This is how I see DARIAH-FI at its present stage, as a building that hosts highly diverse expertise and heterogeneous data, but also teams of people which I visualize in these virtual offices with open doors, connected through corridors and elevators…
{kind=link}
New types of data
As a new data provider DARIAH-FI welcomes the National Library of Finland’s FINNA portal. Open data provided from museum, archives and libraries to Finna.fi will be made available from its API to test pilot scenarios through which not just metadata but also images will be possible to retrieve, enrich and repurpose for data-intensive research. The FINNA-team will work closely with museums to select data. In turn, the teams at Oulu, Tampere and Helsinki universities will work with the FINNA-team to identify scenarios to connect with needs from research communities.
Aalto Semantic Computer Group will be further developing their Sampo system. After ParliamentSampo, launched in parallel to the first DARIAH-FI period, Aalto will turn its focus to producing semantic web portals for Finnish collections of letters, fine and performance arts.
Diverse partners, such as the social science department at the University of Helsinki or a new partner in the ensemble, the University of Oulu, presented their intention to scrap data from the web to make it manageable for research. From popular discussion forums in Finland, to audiovisual content from streamed media; we are expecting that all partners crystallize their plans with regards to what this data will be. The result of this during the first year is that a series of datasets will be identified, enriched and prepared for new analysis methods, which can then be repurposed by DH oriented researchers who have or want to approach them…

The work started in 2022 will continue and partners in Turku, Jyväskylä, Oulu and Helsinki will be developing automated ways and generative methods to enrich textual content both from the web and cultural heritage organizations, with the novelty that these will be combined with new computer-vision methods to enrich visual content opening an avenue for enabling multimodal research.
Partners from Jyväskylä have presented their plans for deploying machine-learning models to enrich scanned archival material including basic information on its visual content. Concerning other heritage data, Turku data science group will harmonize metadata from FENNICA and FINNA using FINTO vocabularies, and geolocation to correct inconsistencies and enable a better integration of data from diverse heritage domains. In turn, TurkuNLP group will further their work in enriching textual web-data focusing on identifying and labeling interactional discourse. Concerning the visual, teams from the University of Helsinki, Oulu and Jyväskylä will develop reliable labeling systems for social media and Finna images, as well as streaming media and game streams.
Another big challenge for these two years is to offer support for research-groups interested or already working with social media, streamed media, surveys or cultural heritage data. Partners from the University of Eastern Finland, Jyväskylä, Oulu and Helsinki will offer support and develop analysis tools in key research areas, based on their “benchmark datasets”. These analysis tools will support e.g. social interaction analysis, speech and written register, dialectology or multimodal elements of communication from large scale social and audiovisual media, a more comprehensive analysis of game streams using both chat and video data, or concepts for tools to support visual cultural heritage analysis.
In a supporting role CSC will coordinate the flow of data between providers and research teams through its platform. In it, partners can deposit data, generate and receive enrichments, demo and implement newly developed tools in safe, remote and storage-efficient ways. Starting this year, CSC will be generating new pipelines to support visual cultural heritage from FINNA and multimodal data from the web, in addition to improving and maintaining its text data support.
Alongside these streams, Tampere University will be guiding all partners to ensure that research communities are involved in this process. This follows the aim of continuously evaluating the infrastructure’s usability, ensuring that needs and requirements from researchers are integrated in the developing work and to strengthen the great need of education in digital scholarship. Ultimately, the goal is to ensure that while all partners continue cooking data and improving their recipes, these are shared and made available for the broader research community to “taste” and implement themselves.
Finally, the coordinators for this season, Risto Turunen (UH), Inés Matres (UH) and Päivi Pihlaja (NLF) will be collaborating closely with partners and facilitating exchange between these diverse teams and the Language Bank of Finland that hosts and manages an essential part of the infrastructures upon which DARIAH-FI develops work.
Images: Inés Matres, digi.kansalliskirjasto.fi, suomi24, X, Twitch, Finna.fi, istock